

Me encontré esta noticia » Preanalytical Errors Identified Via Machine Learning Without Expert Labeling» en la página de la ADLM (Association for Diagnostics & Laboratory and Medicine, anteriormente AACC) y me pareció una excelente alternativa para los amantes programación, el aprendizaje automatizado y desarrollo de nuevos modelos computacionales para mejorar procesos en laboratorios clínicos y otros sectores.
Trasfondo:
Los laboratorios clínicos presentan una serie de procesos para poder generar un reporte confiable a los pacientes. Se divide en tres fases que son: pre analítica, analítica y post analítica. La fase pre analítica hace referencia a ese primer punto de contacto con el paciente, desde el ingreso de la orden médica hasta la toma de muestra, su manipulación y conservación. La fase analítica comprende todos los elementos en donde la muestra es analizada por el profesional de laboratorio, garantizando el control total del proceso para entregar resultados confiables. Y finalmente la fase post analítica es el último paso en donde se entrega el resultado de laboratorio al paciente, en un formato adecuado para su lectura e interpretación, con los datos correctos del paciente, análisis realizado y valores de referencia y demás elementos necesarios.
A nivel hospitalario, se presenta una situación compleja cuando al paciente se le administran líquidos intravenosos. Este es un evento usualmente necesario en todo proceso de hospitalización y hace parte de la práctica médica diaria. Sin embargo cuando esto se presenta, es usual que al pacientes le ordenen mediciones de pruebas de laboratorio. Es aquí donde se puede cometer un error en la fase preanalítica y es tomar la muestra de sangre del paciente para el análisis de pruebas de laboratorio al mismo tiempo se le está pasando soluciones intravenosas con medicamentos o electrolitos, de esta forma es que se puede contaminar la muestra con esos elementos.
La contaminación por líquidos intravenosos es un problema en los errores en la fase preanalítica de los laboratorios clínicos, que aunque no tiene mucha incidencia (1), es uno de los más delicados ya que impacta severamente en el manejo que se le dé al paciente. Un solo resultado que sea liberado bajo esta condición puede alterar falsamente los resultados de pruebas que requieren una conducta clínica inmediata, lo cual hace que al paciente se le modifique el tratamiento en función de estabilizar su falsa condición clínica.
Como identificar el problema:

La identificación de este tipo de problemas en el laboratorio clínico está, en mayor medida, en manos del profesional de laboratorio o los auxiliares de laboratorio. Este tipo de muestras mal tomadas pueden presentar una proporción irregular del paquete celular y del plasma, se evidencia un fenómeno de hemodilución y se genera un volumen más alto de plasma que de paquete globular (la relación al 100% entre paquete globular y plasma normalmente está entre 45:55 respectivamente). Esta situación hace que visiblemente se pueda identificar una posible contaminación con relaciones de 20:80 o incluso de 10:90 por la presencia de soluciones intravenosas.


La otra manera es directamente con los resultados obtenidos, donde apreciamos que pruebas se afectan considerablemente pasando de valores biológicamente aceptables a valores imposibles con la vida. Un ejemplo es el caso del potasio, donde podemos ver con facilidad resultados por encima de 7 mmol/L en un paciente con buenas condiciones y buena función renal; es posible que lo estén tratando con soluciones altas en potasio y esto contamina las muestras tomadas. Las consecuencias de este tipo de problemas son finalmente generar dudas en el tratamiento médico o retrasar el reporte para confirmar la situación.
Cuando son los resultados obtenidos los que permiten la detección de la contaminación, los laboratorios pueden usar herramientas básicas de informática como los chequeos delta (2), consiste en una estimación matemática en donde se revisa el porcentaje de diferencia de un resultado actual frente al último medido y ha demostrado ser de gran ayuda en revisar cambios significativos de los resultados de un paciente y asegurar una acción correctiva frente a un cambio no aceptable biológicamente o preventiva frente a un cambio aceptable que amerite ser informado de forma prioritaria.
Una solución automatizable y viable:

Sin embargo, estos métodos de contención son vulnerables a errores humanos, y no siempre se cuenta con los desarrollos tecnológicos para “bloquear” un resultado dudoso. Una solución a este problema está en la inteligencia artificial, en la línea del “machine learning”, donde se puede desarrollar algoritmos de aprendizaje automático supervisado que ayuda detectar de forma automática la presencia de este tipo de anomalías. Este proceso consiste en enseñarle a la máquina cuales son las características o atributos pertenecientes a un grupo de datos que están relacionados con una condición o estatus determinado, requiere hacer clasificaciones exhaustivas y etiquetar dato por dato, se requiere un buen número de información “enseñada” e identificar qué dato pertenece a qué condición. El problema radica que implementar este tipo de tecnologías es costoso y dispendioso, en su etapa inicial de desarrollo requiere la participación de clasificadores y etiquetadores expertos(3).
Una alternativa moderna que está tomando mucha fuerza en la investigación en ciencias básicas y desarrollo de modelos en inteligencia artificial en diferentes campos es la Aproximación y Proyección de Colectores Uniformes o mas conocido como Uniform Manifold Approximation and Projection (UMAP) (3), existe un estudio que muestra su uso en comunidad de genética de poblaciones para estudiar la estructura de la población (4) y es algo revolucionario ya que se pueden redimensionar datos de alta dimensión en estructuras de datos similares pero de baja dimensión, en función de las variables, y de esta manera logra generar mejores efectos de correlación de variables y comportamiento de los datos. Existe un documento que describe todo su fundamento y algunas de las aplicaciones que tiene este sistema para el machine learning(5).
Uno de los puntos clave del UMAP para el aprendizaje automatizado es el “clustering” que es el agrupamiento de conjuntos de objetos no etiquetados, para agrupar conjuntos de datos denominados clústers. “Cada clúster está formado por una colección de elementos que resultan similares entre sí, pero que poseen elementos diferenciales con respecto a otros objetos pertenecientes al conjunto de datos y que pueden conformar un cluster independiente”(6).
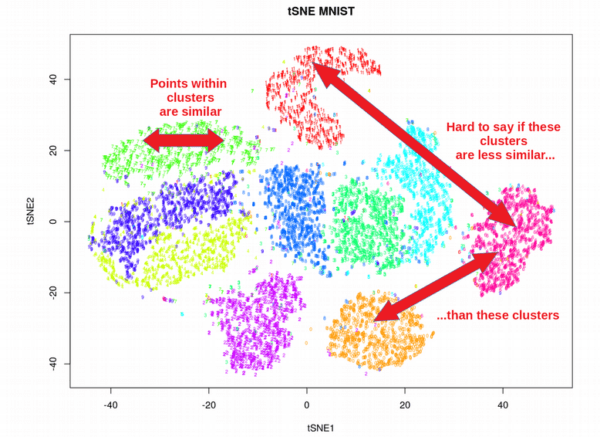
Para el caso de los aprendizajes automatizados no supervisados, el Clustering, sirve para identificar subgrupos de datos de dimensiones similares (características, atributos) para facilitar el proceso de identificación, clasificación y aprendizaje. Sumado a esto, lograr redimensionar el paquete de datos de altas dimensiones a bajas dimensiones hace que la identificación de los datos sea correlacionable y fácil de lograr.
Nicholas C Spies e investigadores (3) entrenaron y probaron un UMAP donde combinaron datos de pacientes reales y muestras contaminadas con fluidos intravenosos de forma simulada para obtener un total de 25.747.291 resultados de 312.721 pacientes que se realizaron un perfil metabólico básico.
Parte de los resultados obtenidos en este estudio indican que la utilización de UMAP evidenciaron valores atípicos sospechosos de contaminación por líquido intravenoso en comparación con las incorporaciones de contaminación simulada, con un valor predictivo positivo de 0,78 de 100 predicciones positivas consecutivas. “De estos, 58 no habían sido detectados previamente por los flujos de trabajo clínicos actuales, y 49 perfiles metabólicos básicos mostraron 56 resultados críticos”.
Un ejemplo de uso, un sin fin de posibilidades:
Finalmente queda la puerta abierta a usar estas herramientas de apoyo en el desarrollo de herramientas tecnológicas que puede en primer lugar darle uso a la gigantesca data que acumula un laboratorio clínico, y segundo plano y quizás el mas importante, darle solución a problemas típicos que afronta un laboratorio para mejorar su desempeño. Estamos acostumbrados a pensar que la Inteligencia Artificial solo la podemos usar en el aspecto creativo de imitar las maravillosas habilidades del ser humano. No alcanzamos a imaginar la cantidad de aplicaciones, que por cierto llevan años desarrollando, en muchos otros conceptos lógicos y matemáticos que están haciendo mas fácil entender y comprender nuestra vida. Es cuestión de tiempo para que personas con habilidades creativas usen la I.A. no para hacer lo imaginable, sino para tocar los límites de lo inimaginable.
AUTOR:
NOTAS:
- Alcantara JC, Alharbi B, Almotairi Y, Alam MJ, Muddathir ARM, Alshaghdali K. Analysis of preanalytical errors in a clinical chemistry laboratory: A 2-year study. Medicine (Baltimore). 2022 Jul 8;101(27):e29853. doi: 10.1097/MD.0000000000029853. PMID: 35801773; PMCID: PMC9259178.
- Kim MS, Park CJ, Namgoong S, Kim SI, Cho YU, Jang S. Effective and Practical Complete Blood Count Delta Check Method and Criteria for the Quality Control of Automated Hematology Analyzers. Ann Lab Med. 2023 Sep 1;43(5):418-424. doi: 10.3343/alm.2023.43.5.418. Epub 2023 Apr 21. PMID: 37080742; PMCID: PMC10151276.
- Nicholas C Spies, Zita Hubler, Vahid Azimi, Ray Zhang, Ronald Jackups, Ann M Gronowski, Christopher W Farnsworth, Mark A Zaydman, Automating the Detection of IV Fluid Contamination Using Unsupervised Machine Learning, Clinical Chemistry, Volume 70, Issue 2, February 2024, Pages 444–452
- Diaz-Papkovich, A., Anderson-Trocmé, L. & Gravel, S. A review of UMAP in population genetics. J Hum Genet 66, 85–91 (2021). https://doi.org/10.1038/s10038-020-00851-4
- McInnes, Leland & Healy, John. (2018). UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction.
- https://taniwa.es/blog/umap/#:~:text=UMAP%20(Uniform%20Manifold%20Approximation%20and,estructura%20de%20los%20datos%20originales.
- Dimensionality Reduction : PCA, tSNE, UMAP – Auriga IT

Deja un comentario